
MySQL官网:https://www.mysql.com (opens new window)
# 一、数据库
# SQL语言
SQL Structured Query Language 结构化查询语言
DDL 数据定义语言
DML 数据操作语言
DCL 数据控制语言
DQL 数据查询语言
结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询语言。
作用:用于存储数据、查询、更新和管理关系数据库系统。
SQL语言包括数据定义(DDL)、数据操纵(DML),数据控制(DCL)和数据查询(DQL)四个部分。
DDL数据定义语言 针对表包括
CREATEALTERDROPDML数据操作语言 针对数据包括
INSERTUPDATEDELETE
# 数据库三大范式
第一范式:列不可分,每列都是不可再分的最小数据单元 ;
第二范式:不存在部分依赖,(只有一个业务主键)行可以唯一区分,主键约束 ;
首先满足第一范式,并且表中非主键列不存在对主键的部分依赖。 第二范式要求每个表只描述一件事情。
第三范式:不存在传递依赖,(确保其他列和主键直接相关)表的非主键属性不能依赖与其他表的非主键属性 外键约束 ;
第三范式定义是,满足第二范式,并且表中的列不存在对非主键列的传递依赖。
三大范式是一级一级依赖的,第二范式建立在第一范式上,第三范式建立第一第二范式上 。
# JDBC
JDBC,Java数据库连接,是一种用于执行SQL语句的Java API。
JDBC访问数据库步骤:
1、注册驱动;
2、建立数据库连接Connection;
3、获取SQL命令发布器Statement;
4、创建SQL语句;
5、发布SQL命令,返回结果ResultSet;
6、便利显示结果,关闭连接。
# 事务
事务是一组原子性的SQL查询,或者是一个独立的工作单元。
# ACID
A Atomicity 原子性
C Consistency 一致性
I Isolation 隔离性
D Durability 持久性
A——原子性,操作要么一起提交,要么一起回滚;
C——一致性,数据状态的一致性;一旦事务完成(不管成功还是失败),系统必须确保它所建模的业
务处于一致的状态;
I——隔离性,事务之间互不影响。一个事务所做的修改,在提交前,对其他事务不可见;(MVCC保证事务的隔离性)
D——持久性,事务提交后,修改记录永久保存到数据库。(redo日志保证事务的持久性)
# ACID靠什么保证
A: 原子性由undo log日志来保证;在undo log日志中,记录了用于回滚的行记录,用于事务的回滚,从而保证了事务的原子性。
C:一致性是由其他三大特性来保证;满足了其他三大特性,也就保证了业务的一致性。
I:隔离性由MVCC来保证;
D:持久性由内存 + redo log日志 + binlog日志来保证;
mysql在写入数据时,会在内存BufferPoll缓存池、redo log日志、binlog日志 中都进行记录。
先将行记录更新至BufferPool进行缓存,再写入redo日志,再把记录写入binlog日志后,将redo日志中记录进行commit标记,而后提交事务;而缓存池BufferPool中的数据,会以Page为单位,随机写入磁盘持久化。
# MySQL事务的隔离级别
READ UNCOMMITTED 未提交读
READ COMMITTED 读已提交
REPEATABLE READ(RR ) 可重复读
SERIALIZABLE 串行化
Oirty Read 脏读
在SQL标准中,定义了四种个隔离级别。

未提交读
事务可以读取未提交的数据。——可能出现脏读
读已提交
一个事务只能看见已提交事务所做的修改。——解决了脏读,可能出现不可重复读
可重复读
RR(默认)是MySQL默认的隔离级别。
保证了在同一个事务中,多次读取同样记录的结果是一致的。——解决了不可重复读,可能出现幻读
InnoDB存储引擎通过MVCC来解决幻读问题。串行化
强制事务串行执行,会在读取的每一行数据都加锁。
# 查看事务隔离级别
MySQL 5.x 使用如下命令查看 MySQL 隔离级别:
SELECT @@GLOBAL.tx_isolation, @@tx_isolation;
全局隔离级别和当前会话隔离级别皆是如此。
MySQL 8 开始,通过如下命令查看 MySQL 默认隔离级别:
SELECT @@GLOBAL.transaction_isolation, @@transaction_isolation;
# 修改隔离级别
通过如下命令可以修改隔离级别(建议开发者在修改时修改当前 session 隔离级别即可,不用修改全局的隔离级别):
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
上面这条 SQL 表示将当前 session 的数据库隔离级别设置为 READ UNCOMMITTED,设置成功后,再次查询隔离级别,发现当前 session 的隔离级别已经变了。
注意,如果只是修改了当前 session 的隔离级别,则换一个 session 之后,隔离级别又会恢复到默认的隔离级别,所以我们测试时,修改当前 session 的隔离级别即可。
# 视图
视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作。
视图通常是有一个表或者多个表的行或列的子集。对视图的修改不影响基本表,它使得我们获取数据更容易。
# 内联接
内联接(Inner Join):匹配2张表中相关联的记录。
# 外联接
左外联接(Left Outer Join):除了匹配2张表中相关联的记录外,还会匹配左表中剩余的记录,右表中未匹配到的字段用NULL表示。
右外联接(Right Outer Join):除了匹配2张表中相关联的记录外,还会匹配右表中剩余的记录,左表中未匹配到的字段用NULL表示。
在判定左表和右表时,要根据表名出现在Outer Join的左右位置关系。
# 锁
当数据库有并发事务的时候,可能会产生数据的不一致,这时候需要一些机制来保证访问的次序,锁机制就是这样的一个机制。
锁分类
按分类
乐观锁
悲观锁
按锁的类别
- 共享锁(读锁)
- 排他锁(写锁)
按锁的粒度分类
- 行级锁
- 表级锁
- 页级锁
# 乐观锁
乐观锁认为一个用户读数据的时候,别人不会去写自己所读的数据;悲观锁就刚好相反,觉得自己读数据库的时候,别人可能刚好在写自己刚读的数据,其实就是持一种比较保守的态度;时间戳就是不加锁,通过时间戳来控制并发出现的问题。
# 悲观锁
悲观锁就是在读取数据的时候,为了不让别人修改自己读取的数据,就会先对自己读取的数据加锁,只有自己把数据读完了,才允许别人修改那部分数据,或者反过来说,就是自己修改某条数据的时候,不允许别人读取该数据,只有等自己的整个事务提交了,才释放自己加上的锁,才允许其他用户访问那部分数据。
共享锁(读锁)和排它锁(写锁)是悲观锁的不同的实现
# 共享锁
共享锁又叫做读锁,所有的事务只能对其进行读操作不能写操作,加上共享锁后在事务结束之前 其他事务只能再加共享锁,除此之外其他任何类型的锁都不能再加了。
当用户要进行数据的读取时,对数据加上共享锁。共享锁可以同时加上多个。
# 排他锁
排他锁又叫做写锁。 当用户要进行数据的写入时,对数据加上排他锁。排他锁只可以加一个,他和其他的排他锁,共享锁都相斥。
# 行级锁
行级锁 行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁 和 排他锁。
特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
InnoDB 的行锁是在有索引的情况下,没有索引的表会升级为表锁,是锁定全表的。
# 表级锁
表级锁 表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。最常使用的MYISAM与INNODB都支持表级锁定。表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。
特点:开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
# 页级锁
页级锁 页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。
特点:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
总结:InnoDB实现了行级锁,页级锁,表级锁。他们的加锁开销从大到小,并发能力也是从大到小。
# 死锁
两个或两个以上事务在同一资源上相互占用,导致都等待对方释放锁。
产生原因:
1、真正的数据冲突;
2、存储引擎的实现方式导致;
解决:
InnoDB解决死锁的方法——死锁回滚法,将最少行级排他锁的事务进行回滚。
大多数情况MySQL可以自动检测死锁并回滚产生死锁的那个事务,但是有些情况MySQL没法自动检测死锁 。
测试死锁:
set tx_isolation='repeatable-read';
Session_1执行:select * from account where id=1 for update;
Session_2执行:select * from account where id=2 for update;
Session_1执行:select * from account where id=2 for update;
Session_2执行:select * from account where id=1 for update;
2
3
4
5
查看近期死锁日志信息:
show engine innodb status\G;
查看INFORMATION_SCHEMA系统库锁相关数据表:
‐‐ 查看事务
select * from INFORMATION_SCHEMA.INNODB_TRX;
‐‐ 查看锁
select * from INFORMATION_SCHEMA.INNODB_LOCKS;
‐‐ 查看锁等待
select * from INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
‐‐ 释放锁,trx_mysql_thread_id可以从INNODB_TRX表里查看到
kill trx_mysql_thread_id
‐‐ 查看锁等待详细信息
show engine innodb status\G;
2
3
4
5
6
7
8
9
10
11
12
锁优化建议
- 尽可能让所有数据检索都通过索引来完成,避免无索引使得行锁升级为表锁;
- 合理设计索引,尽量缩小锁的范围;
- 尽可能减少检索条件范围,避免间隙锁;
- 尽量控制事务大小,减少锁定资源量和时间长度,涉及事务加锁的SQL尽量放在事务最后执行;
- 尽可能低级别事务隔离。
# 二、MySQL逻辑架构
三层架构
- 第一层:客户端——授权认证
- 第二层:服务器层——查询解析、分析、优化、缓存、存储过程、视图、触发器、表的定义。
- 第三层:存储引擎层——数据的存储和提取、索引、事务、行级锁

# 三、数据结构
Data Structure Visualizations 数据结构可视化
- 二叉树
- 红黑树(二叉平衡树)
- B Tree
- B + Tree
- Hash
# 二叉树
Binary Search Tree

特点
- 只有一个根节点;
- 每个节点只有2个子节点;
- 左边的节点比它小,称为左子树;右边的节点比它大,称为右子树。
- 最后一层节点称为叶子节点。
不足
对于单边递增的列,用二叉树存储即相当于链表,不可取。
# 红黑树
Red/Black Tree
红黑树,又称二叉平衡树。是在二叉树的基础上,通过特定操作,保持二叉树的平衡。
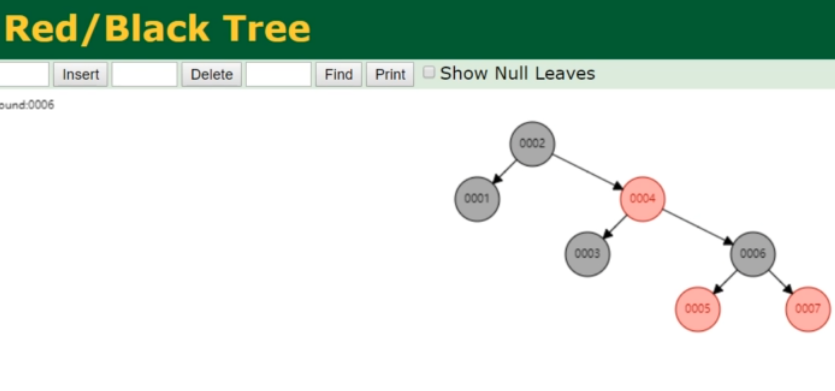
特点
- 根节点是黑色,子节点是红色或黑色。
- 每个红色节点上的2个子节点都是黑色。
- 从根节点到叶子不能有2个连接的红色节点。
- 所有最长的路径都有相同数据的黑色节点。
不足
对于大数据,红黑树的高度不可控,不可取。
# B Tree
B balance 平衡
多路搜索树
B Tree树线上可视化网址 (opens new window)

特点
- 所有索引元素不重复;
- 节点中的数据索引从左到右递增排列;
- 叶子节点具有相同的深度,且指针为空;
- 每个节点下存储对应的
data。
不足
当data数据过大,将导致每一页的节点数变小,则导致树的深度增大。
# B + Tree
B + Tree树线上可视化网址 (opens new window)

特点
所有索引元素可重复(冗余);
非叶子节点不存储data;
所有data或者key都存储在叶子节点;
- 聚簇索引:叶子节点保存所有索引字段;
- 非聚簇索引:只存储了当前key的值;
叶子节点之间用指针连接,提高区间访问性能;
B+Tree的高度一般在2~4层;
所有值都按顺序存储;
每一个叶子到根节点的距离相等。
# Hash结构
对索引的KEY进行HASH计算,从而定位出数据存储的位置。

不足
- 不支持范围查询:仅能满足等于(=)、包含(IN)这些等值查询,不支持范围查询。
- 不支持排序:不支持使用索引进行排序。
- 回表查询:Hash索引必须进行回表查询数据。
# 四、存储引擎
主要存储引擎:
- MyISAM
- InnoDB
存储引擎最终作用于表上,针对表进行区分。
# MyISAM
在MySQL5.1之前,MyISAM是默认的存储引擎。
# 特性
- 全文索引,支持BLOB和TEXT的前500个字符索引,支持全文索引;
- 压缩表,对于不会进行修改的表,支持压缩表,极大减少磁盘空间占用;
- 支持延迟更新索引,极大提升写入性能;
- 在表有读取查询的同时,支持往表中插入新纪录;
缺点
- 不支持事务;
- 不支持行级锁,读取时对需要读到的所有表加锁,写入时则对表加排它锁;
- 不支持外键;
- 崩溃后无法安全恢复,
# 存储
将表存储在3个文件:
- 数据表结构(定义)文件——
.frm文件 - 数据文件——
.MYD文件 - 索引文件——
.MYI文件
# MyISAM索引结构
非聚簇索引(主键索引和非主键索引都是该结构)
叶子节点只包含了主键对应数据的地址,索引和数据分开存储。

# InnoDB
MySQL(5.1+),InnoDB是默认的事务型引擎。
# 特性
四大特性:
- 插入缓冲 insert buffer
- 二次写 double write
- 自适应哈希索引 ahi
- 预读 read ahead
其他特性:
事务、行级锁、自动崩溃恢复、基于聚簇索引、用MVCC来支持高并发。
# 存储
每个表有2个文件:
- 表结构文件——
.frm - 数据索引文件——
.ibd
数据文件是按B+Tree组织的一个索引结构文件。
每建一个索引,在.ibd文件中就加一个B+Tree组织的结构数据。
# InnoDB索引结构
聚簇索引结构(主键索引)
一张表最多只有一个聚簇索引。
叶子节点包含了完整的数据记录。

二级索引机构(非主键索引)
InnoDB的二级索引的叶子节点存储的是聚簇索引的KEY。目的是为了数据一致性和节省存储空间。
# InnoDB-页(Page)
InnoDB存储引擎中有页(Page)的概念,页是其磁盘管理的最小单位。InnoDB默认每一个页的大小为16KB(16384字节),可通过参数查看show global status like 'Innodb_page_size';
# 五、索引
索引,是帮助MySQL高效获取数据的一种排好序的数据结构。
索引是在存储引擎层。
# 索引设计的原则
索引,是为了查询更快,占用空间更小。设计时,要遵循代码先行,索引后上。
索引设计原则:
- 索引很好,但不可无限制使用;
- 适合索引的列是出现在
where子句、join子句、group by子句、order by子句; - 较频繁查询条件的字段才去创建索引;
- 频繁修改的字段不去创建索引;
- 最左前缀匹配原则;
- 数量小的表不必建索引;
- 小基数字段不建索引;
- 长字符串采用前缀索引,大文本字段不建索引;
- 尽量使用联合索引,一张表可建立2~3个联合索引(读多写少);
- 要根据实际业务,读多写也多,则需考虑DML操作时的性能;
# 索引优点
- 索引将随机I/O变为顺序I/O;
- 索引大大减少了服务器需要扫描的数据量;
- 索引可以帮助服务器避免文件排序(file sort)和临时表;
# 索引影响
索引不是万能的,不要过度依赖索引。
索引需要额外的磁盘空间,并且会降低写操作的性能。
在DML操作时,索引会进行更新甚至重构;索引列越多,这个时间将越长。DML操作将多付出4~5次磁盘I/O。
# 索引类型
# 按数据结构分
聚簇索引
一张表只有一个聚簇索引。
聚簇索引是只将索引和数据存储在一起,找到索引也就找到了数据。
非聚簇索引
非聚簇索引是将索引和数据分开存储。索引结构的叶子节点指向数据的对应行,若要找到全部数据,需要进行二次查找(回表)。
# 按字段分
主键索引
由主键字段构建的索引结构。
辅助索引
由非主键字段构建的索引结构。
二级索引
由非主键字段构建的索引结构(单字段)。
联合索引、多列索引
由多个字段联合构建的索引结构。若要命中联合索引,需按照构建索引时的顺序挨个检索。
前缀索引
使用字段值的前几个字符建立的索引。可以使用
left(col, n)/ count(*)来计算选出最合适的长度,进行前缀截取。
# 最左前缀原则
最左优先,在创建多列索引时,将使用最频繁的一列放在左边。
最左前缀匹配原则:
- 从左至右一直匹配,直到遇到范围查询停止匹配。
当只有等值查询时,建立多列索引顺序可任意。因为MySQL查询优化器会帮你优化成索引建立的顺序。
# 覆盖索引
一般指在联合索引中,是指一种现象。
当使用select查询的字段,在联合索引就全部包含了,不需要再回表查询其他字段了。这种情况称之为覆盖索引。
覆盖索引一般针对的是辅助索引,整个查询结果只通过辅助索引就能拿到结果,不需要通过辅助索引树找到主键,再通过主键去主键索引树里获取其它字段值 。
# trace工具
trace可用于查看cost成本,选择cost值较小的建立索引。
局部会话开启trace
‐‐开启trace set session optimizer_trace="enabled=on",end_markers_in_json=on;1
2在每次查询时查看trace
select * from employees where name > 'a' order by position; SELECT * FROM information_schema.OPTIMIZER_TRACE;1
2
# 索引优化实践
ICP Index Condition Pushdown 索引下推
全值匹配,对索引中所有列都指定具体值;
最左前缀原则;
不要在索引列上进行函数等运算操作,会导致索引失效,从而转向全表扫描;
尽量使用覆盖索引,减少使用
select * from的情况;使用不等于条件时(!= 或者 <>)可能不使用索引,从而转向全表扫描;
is null、is not null一般无法使用索引;like语句以通配符(%abc..)开头时,无法使用索引;字段类型为数值,则查询值类型也设置为数值,若为字符串,则加单引号;
where age = 20 and name = 'ccc';1少用
or或者in,因为不一定使用索引,MySQL内部会用cost成本计算评估是否使用索引。范围查询,数据量太大,可拆分为多个小范围的查询条件进行优化;
索引下推(
ICP):联合索引中,对所包含的所有字段先判断,再回表,将有效减少回表次数。where与order by,优先考虑wehere条件使用索引;先整合业务,再设计索引,多用联合索引,尽可能使用2~3个联合索引,抗下90%的查询,确保大多数SQL都可利用二级索引;
# 索引使用案例

# Mysql表索引类型
| 索引类型 | 描述 |
|---|---|
| FULLTEXT | 全文搜索索引 |
| MORMAL | 普通索引 |
| SPATIAL | 空间索引 |
| UNIQUE | 唯一索引 |
索引命名规范:
- 主键索引名为
pk_字段名; - 唯一索引名为
uk_字段名; - 普通索引名为
idx_字段名;
# 六、explain工具
使用explain关键字可以模拟优化器执行SQL语句,分析你的查询语句、结构的性能瓶颈,返回该SQL执行计划的信息。
在 select 语句之前增加 explain 关键字,MySQL 会在查询上设置一个标记,执行查询会返回执行计划的信息,而不是执行这条SQL。
Explain分析示例:参考官方文档 (opens new window)
# explain使用
explain select * from sys_user;

explain 两个变种:explain extended、explain partitions
- explain extended
explain extended select * from sys_user where id = 1;
show warnings;
2


会在 explain 的基础上额外提供一些查询优化的信息。
紧随其后通过 show warnings 命令可以得到优化后的查询语句,从而看出优化器优化了什么。
额外还有 filtered 列,是一个半分比的值,rows *filtered/100 可以估算出将要和 explain 中前一个表进行连接的行数(前一个表指 explain 中的id值比当前表id值小的表)。
- explain partitions
explain partitions select * from sys_user where id = 1;

相比 explain 多了个 partitions 关键字,如果查询是基于分区表的话,会显示查询将访问的分区。
# explain说明
以下为explain 展示列的信息。

# 1、id列
id列的编号是 select 的序列号,有几个 select 就有几个id,并且id的顺序是按 select 出现的顺序增长的。
id列越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行。
# 2、select_type列
select_type 表示对应行是简单还是复杂的查询。
simple:简单查询,查询不包含子查询和unionprimary:复杂查询中最外层的 selectsubquery:包含在 select 中的子查询derived:包含在 from 子句中的子查询。MySQL会将结果存放在一个临时表中,也称为派生表(derived的英文含义)union:在 union 中的第二个和随后的 select。
# 3、table列
这一列表示 explain 的一行正在访问哪个表。
- 当 from 子句中有子查询时,table列是 (derivenN) 格式,表示当前查询依赖 id=N 的查询,于是先执行 id=N 的查询。
- 当有 union 时,UNION RESULT 的 table 列的值为(union1,2),1和2表示参与 union 的 select 行id。
# 4、type列
这一列表示关联类型或访问类型。即MySQL决定如何查找表中的行,查找数据行记录的大概范围。
依次从最优到最差分别为:
system > const > eq_ref > ref > range > index > ALL
一般来说,得保证查询达到range级别,最好达到ref。
NULL:mysql能够在优化阶段分解查询语句,在执行阶段用不着再访问表或索引。例如:在索引列中选取最小值,可以单独查找索引来完成,不需要在执行时访问表。
explain select min(id) from sys_user;1const:mysql能对查询的某部分进行优化并将其转化成一个常量(可以看show warnings 的结果)。用于
primary key或unique key的列与常数比较时,匹配结果只有一行数据;读取1次,速度比较快。select * from sys_user where id = 1;1system:system是const的特例,表里只有一行数据,type为system 。1eq_ref:唯一索引(primary key或unique key)索引的字段被联接使用(on)。explain select * from rel_user_role left join sys_user on rel_user_role.user_id = sys_user.id;1ref:相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一索引的部分前缀,索引要和某个值相比较,可能会找到多个符合条件的行。- 简单 select 查询,real_name是普通索引(非唯一索引)
explain select * from sys_user where real_name = '超级管理员';1- 关联表查询,idx_film_actor_id是film_id和actor_id的联合索引,这里使用到了film_actor的左边前缀film_id部分。
explain select film_id from film left join film_actor on film.id = film_actor.fi lm_id;1
2range:范围扫描通常出现在in(),between,>,<,>=等操作中。使用一个索引来检索给定范围的行。explain select * from sys_user where id > 1;1index:扫描全索引就能拿到结果。一般是扫描某个二级索引,这种扫描不会从索引树根节点开始快速查找,而是直接对二级索引的叶子节点遍历和扫描,速度还是比较慢的,这种查询一般为使用覆盖索引,二级索引一般比较小,所以这种通常比ALL快一些。
explain select id, username from sys_user;1ALL:即全表扫描,扫描聚簇索引的所有叶子节点。通常情况下这需要增加索引来进行优化了。explain select * from sys_user;1
# 5、possible_keys列
这一列显示查询可能使用哪些索引来查找。
- 可能出现 possible_keys 有列,而 key 显示 NULL 的情况。这种情况是因为表中数据不多,mysql认为索引对此查询帮助不大,选择了全表查询。
- 如果该列是NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。
# 6、key列
这一列显示mysql实际采用哪个索引来优化对该表的访问。
如果没有使用索引,则该列是 NULL。如果想强制mysql使用或忽视possible_keys列中的索引,在查询中使用 force index或者ignore index。
# 7、key_len列
这一列显示了MySQL在索引里使用的字节数,通过这个值可以算出具体使用了索引中的哪些列。
举例来说,表sys_user的联合索引 idx_type_id 由 user_id 和 type_id 两个int列组成,并且每个int是4字节。通过结果中的key_len=4可推断出查询使用了第一个列:user_id列来执行索引查找。
key_len计算规则如下:
字符串,
char(n)和varchar(n)5.0.3以后版本中,
n均代表字符数,而不是字节数。- char(n)、varchar(n):长度n就表示可以存n个字符(字母/汉字)。
计算字节:若是utf-8,一个数字或字母占1个字节,一个汉字占3个字节。
char(n):如果存汉字,长度就是 3n 字节
varchar(n):如果存汉字,则长度是 3n + 2 字节,加的2字节用来存储字符串长度,因为varchar是变长字符串
数值类型
tinyint:1字节smallint:2字节int:4字节bigint:8字节
时间类型
date:3字节timestamp:4字节datetime:8字节
如果字段允许为
NULL,额外需要1字节记录是否为 NULL
索引最大长度是768字节,当字符串过长时,MySQL会做一个类似左前缀索引的处理,将前半部分的字符提取出来做索引。
# 8、ref列
这一列显示了在key列记录的索引中,表查找值所用到的列或常量。常见的有:
const(常量);- 字段名(例:film.id)。
# 9、rows列
这一列是mysql估计要读取并检测的行数,注意这个不是结果集里的行数。
# 10、Extra列
这一列展示的是额外信息。常见的重要值如下:
Using index:- 当
where查询中,表示使用覆盖索引 ; - 使用
order by子句,表示使用索引本身完成排序;
- 当
Using where:使用where语句来处理结果,并且查询的列未被索引覆盖。Using index condition:查询的列不完全被索引覆盖,where条件中是一个前导列的范围。Using temporary:mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。
Using filesort:文件排序将用外部排序而不是索引排序,数据较小时在内存排序,否则在磁盘排序。
这种情况下一般也是要考虑使用索引来优化的。
可通过
trace工具查看sort_code的值。单路排序:一次性取出所有字段,在
sort buffer中排序;<sort_key, additional_fields>1双路排序(回表排序):先根据
order by取出ID和排序字段,在sort buffer中排序,之后再回表去除其他所有字段。<sort_key, rowid>1
# 七、SQL命令
SQL 基础教程中文文档 (opens new window)
# SELECT执行顺序
FROM > JOIN > ON > WHERE > GROUP BY > HAVING > SELECT > DISTINCT > ORDER BY > LIMIT
# mysql8修改root密码
-- mysql8.0 修改root密码;
-- 1. 进入容器内部
docker exec -it 容器ID /bin/bash
-- 2. 进入mysql服务
mysql -uroot -p
-- 3. 使用mysql库,进行修改
use mysql;
-- 将字段置为空
update user set authentication_string='' where user='root';
-- 修改密码为root
ALTER user 'root'@'%' IDENTIFIED BY '123456';
flush privileges;
2
3
4
5
6
7
8
9
10
11
12
13
14
# 创建库
CREATE DATABASE 'kim_db' CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
# 创建用户
create user 'kim'@'%' identified by 'kim';
-- 授予PROESS权限
GRANT PROCESS ON *.* TO 'kim'@'%';
FLUSH PRIVILEGES;
2
3
4
查看用户
SELECT User, Host FROM mysql.user;
删除用户
DROP USER '用户名'@'主机名';
修改用户密码
ALTER USER 'kim'@'%' IDENTIFIED BY '新密码';
# 授权
授权全部权限
grant all on kim_db.* to kim; FLUSH PRIVILEGES;1
2授权部分权限
-- 1 授权当前用户只能对数据库的表进行DML GRANT SELECT, INSERT, UPDATE, DELETE ON database_name.* TO 'kim'@'%'; -- 2 授权对表的创建、表的修改、索引相关操作权限 GRANT CREATE, ALTER, INDEX ON database_name.* TO 'kim'@'%'; -- 3 授权对视图的创建、查询操作权限 GRANT CREATE VIEW, SHOW VIEW ON database_name.* TO 'kim'@'%'; FLUSH PRIVILEGES;1
2
3
4
5
6
7查看当前用户的权限
show GRANTS for 'kim'@'%';1
# 取消授权
取消用户全部权限
-- 1. 撤销用户对某个数据库的全部权限 REVOKE ALL PRIVILEGES ON kim_db.* FROM 'kim'@'%'; FLUSH PRIVILEGES;1
2
3取消用户部门权限
-- 2. 撤销用户对某个数据库的部分权限 REVOKE INSERT, UPDATE, DELETE ON database_name.* FROM 'user_name'@'%'; -- 3. 撤销用户对某个数据库的某张表的部分权限 REVOKE INSERT, UPDATE, DELETE ON database_name.table_name FROM 'user_name'@'%'; FLUSH PRIVILEGES;1
2
3
4
5
# 八、函数
# 为空
查询字段为空或者为null
(name IS NULL or name = '')
-- 或者
(ISNULL(name) or name = '')
2
3
4
# 不为空
查询字段不为空并且不为null
name IS NOT NULL and LENGTH(TRIM(name))>0
# GROUP_CONCAT
多行数据用逗号拼接返回一行
SELECT GROUP_CONCAT( `name` SEPARATOR ',' ) FROM sys_user
# REPLACE
将某个字段的部分字符串替换为指定字符
UPDATE sys_user set name = REPLACE(name,'aaa','bbb');
# INSTR
格式:instr(源字符串, 目标字符串)
作用:用于返回子串substr在字符串str中第一次出现的索引位置,没有找到子串时返回0。并且检索不区分大小写。
SELECT (INSTR("abc",'b') > 0)
# DATE_FORMAT
作用:用于格式化数据库日期。
示例:筛选申请时间为指定日期的数据。
<if test="data.requestDate != null">
AND DATE_FORMAT(request_date,'%y%m%d') = DATE_FORMAT(#{data.requestDate},'%y%m%d')
</if>
2
3
# LAST_DAY
作用:获取当前年月的最后一天日期
SELECT LAST_DAY(CURDATE()) AS last_day_of_current_month;
# DATEDIFF
作用:比较日期字段
示例:比较当前年月的最后一天日期,是否小于等于字段值。
SELECT * FROM test_table WHERE DATEDIFF(using_date, LAST_DAY(CURDATE())) <= 0;
# 九、MySQL高级
# 查询性能优化
衡量查询开销的三个指标:
- 响应时间;
- 扫描的行数(存储引擎检索);
- 返回的行数(服务器处理、分析)。
查询性能优化包括:
- 查询SQL优化
- 索引优化
- 库表结构优化
查询性能看响应时间。我们把查询看作一个任务,由一系列子任务组成。每个子任务都会消耗一定时间。
优化查询,实际上要优化其子任务。要么消除一些子任务,要么减少子任务的执行次数,要么让子任务执行更快。
优化的目的就是减少和消除某些额外操作所花费的时间。
查询的生命周期:
从客户端 ——> 到服务端上解析、优化、生成执行计划 ——> 调用执行引擎进行读取 ——> 将结果返回给客户端。
优化数据访问
查询性能低,最基本的原因是访问的数据太多。那么通过减少访问的数据量进行优化。
- 存储引擎层:确认是否检索了大量超过需要的行或列;
- 服务器层:确认是否分析了大量超过需要的行。
多余的数据可带来额外的负担,增加网络开销,消耗CPU和内存资源。
# MySQL生命周期
- 客户端:发送SQL;
- 连接器:管理连接、权限校验;
- 解析器:SQL解析,包括语法解析、词法解析;
- 预处理器:生成语法树;
- 查询优化器:生成执行计划,选择索引;
- 查询执行器:API接口调用存储引擎;
- 存储引擎:读写磁盘数据。

# SQL执行过程
TODO
# 慢查询日志
MySQL慢查询日志种,记录了查询的响应时间、扫描行数、返回的行数。检查慢查询日志,是找出扫描行数过多的查询的好方法。
可以根据监控后台的一些慢SQL,针对这些慢SQL查询做特定的索引优化。
关于慢SQL查询,可以参考这篇文章:https://blog.csdn.net/qq_40884473/article/details/89455740 (opens new window)
分析慢查询:
1、在存储引擎层,是否检索了大量超过需要的行或列(扫描的行数,存储层检索)。
2、在服务层是否解析大量非必须数据(返回的行数,服务层分析处理)。
解决慢查询:
- 合理用limit;
- 多表联查只取所需列;
- 不用*;
- 加缓存Redis;
开启慢查询日志
在my.ini中进行设置。
slow_query_log=1,1为开启,默认0为关闭;slow_query_file=“”,文件位置;long_query_time=10,阈值,秒;
注意:开启慢查询,会影响性能。一般只在调优的时候开启,可在从库中开启进行调优,优化之后再关闭。
日志分析工具
MySQL提供了一个工具——mysqldumpslow,用于分析日志、查找、分析SQL。
# bin-log归档日志
Binlog日志:是Server层,用于恢复磁盘数据。
# Undo回滚日志
Undo日志: 是InnoDB提供,用于回滚行记录到某一个版本,随机I/O;
# Redo恢复日志
Redo日志:是InnoDB提供,用于恢复BufferPool中某一Page数据,顺序写;
# MVCC
# BufferPool缓存机制
# 十、MySQL安装
# Windows安装
MySQL官方下载地址(latest) (opens new window)
MySQL官方下载地址(历史版本) (opens new window)
# MySQL5.6
MySQL(5.6版本)安装(Windows环境) (opens new window)
# MySQL8
自定义安装解压版,本次安装版本为
mysql-8.0.19-winx64.zip
1、解压
解压ZIP包至指定目录并重命名,最终路径为D:\install_java\mysql\mysql8
2、创建my.ini文件
解压版不包含 my.ini 文件,需要自己创建。在解压后的根目录下,创建一个my.ini 文件。
[mysqld]
# 设置3306端口
port=3306
# 设置mysql的安装目录 ----------此处修改为自己的配置------------
basedir=D:\install_java\mysql\mysql8
# 设置mysql数据库的数据的存放目录 ---------此处修改为自己的配置--
datadir=D:\install_java\mysql\mysql8\data
# 允许最大连接数
max_connections=200
# 允许连接失败的次数。
max_connect_errors=10
# 服务端使用的字符集默认为utf8mb4
character-set-server=utf8mb4
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 默认使用“mysql_native_password”插件认证
#mysql_native_password
default_authentication_plugin=mysql_native_password
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8mb4
[client]
# 设置mysql客户端连接服务端时默认使用的端口
port=3306
default-character-set=utf8mb4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
注意:修改自己的安装目录
3、安装
使用管理员身份运行CMD,进入解压的bin目录。
D:
cd D:\install_java\mysql\mysql8\bin
2
a、初始化
mysqld --initialize --console
注意:执行完之后,记录结尾的密码,后面要手动输入。(
root@localhost:之后的就是密码)
b、安装MySQL服务
mysqld --install mysql
c、启动MySQL服务
net start mysql
4、修改密码
连接MySQL,修改密码。
mysql -uroot -p
注意:此次手动输入之前的随机密码。
修改密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'root';
5、配置环境变量
a、新建系统变量MYSQL_HOME,值为MySQL安装路径。
MYSQL_HOME
D:\install_java\mysql\mysql8
2
b、在PATH中加入以下代码。
%MYSQL_HOME%
%MYSQL_HOME%\bin
2
之后即可通过MySQL可视化工具——Navicat进行连接测试。
6、查看MySQL安装版本
mysqld --help
# 卸载MySQL
Windows安装MySQL怎么彻底卸载干净,如下操作。
1、关闭MySQL服务
在任务管理器中,找到服务里面的mysql(找到相关名称即可,可能你的电脑是MySQLxxx),右键点击停止,结束MySQL服务。
2、删除MySQL服务
打开CMD(以管理员身份),执行如下命令删除MySQL服务。
sc delete mysql
这里的mysql需要换成你电脑的服务名称,就是刚刚停止的那个名称。
3、删除MySQL安装目录
找到MySQL安装位置,右键删除。
4、清理注册表
打开命令框(win+R),输入regedit打开注册表编辑器。
文件路径下:HKEY_LOCAL_MACHINE\SYSTEM\ControlSet002\Services\Eventlog\Application*
找到MySQLD Service以及MYSQL进行删除(如果没有就可以忽略)。
5、其他MySQL文件
打开搜索神器Everything。
在你的电脑可能会有多个或者不同的ControlSet00x*,都要将其中的MySQL删掉。
6、删除环境变量配置
打开系统环境变量,将MySQL变量、Path中配置统统删掉。
# Linux安装
MySQL5.7的安装与配置(centos7环境) (opens new window)
# Docker安装
MySQL 5.7安装
docker-compose.yml(5.7)
mkdir -p /usr/local/docker/mysql
cd /usr/local/docker/mysql
vi docker-compose.yml
2
3
version: '3.3'
services:
db:
image: mysql:5.7
restart: always
environment:
MYSQL_ROOT_PASSWORD: 123456
command:
--default-authentication-plugin=mysql_native_password
--character-set-server=utf8mb4
--collation-server=utf8mb4_general_ci
--explicit_defaults_for_timestamp=true
--lower_case_table_names=1
ports:
- 3306:3306
volumes:
- ./data:/var/lib/mysql
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
MySQL 8.x安装
docker-compose.yml(8.x)
mkdir -p /usr/local/docker/mysql8
cd /usr/local/docker/mysql8
vi docker-compose.yml
2
3
version: '3.3'
services:
db:
image: mysql:8.0
restart: always
environment:
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: 123456
command:
--default-authentication-plugin=mysql_native_password
--character-set-server=utf8mb4
--collation-server=utf8mb4_general_ci
--explicit_defaults_for_timestamp=true
--lower_case_table_names=1
--slow_query_log=ON
--slow_query_log_file=/var/lib/mysql/mysql-slow.log
--long_query_time=2
--log-bin=mysql-bin
--server-id=1
--expire_logs_days=7
--max_binlog_size=100m
ports:
- 3306:3306
volumes:
- ./data/mysql/data/:/var/lib/mysql/
- ./data/mysql/logs/:/var/lib/logs/
- ./data/mysql/conf/:/etc/mysql/conf.d/
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 参数配置
1、开启慢查询
--slow_query_log=on
--slow_query_log_file=/var/lib/mysql/mysql-slow.log
--long_query_time=2
2
3
- 打开慢查询日志开关的时候,会影响所有正在访问当前MySQL server的客户端。
- 慢查询日志存储位置。
- 慢查询时间的单位秒,默认时间为10s。
2、开启慢查询
--log-bin=mysql-bin
--server-id=1
--expire_logs_days=7
--max_binlog_size=100m
2
3
4
log-bin:开启二进制日志功能,名字可以随便取。server-id:同一局域网内注意要唯一同一局域网内注意要唯一。expire_logs_days:配置定时清理,自动清理7天前的log文件。max_binlog_size:binlog每个日志文件大小。binlog_format:binlog日志格式,MySQL默认采用的是STATEMENT,建议使用MIXED。- STATEMENT模式(SBR):基于SQL语句的复制(statement-based replication),每一条会修改数据的sql语句都会记录到binlog中。
- ROW模式(RBR):基于行的复制(row-based replication),不记录每条sql语句的上下文信息,仅记录哪条数据被修改了,修改成什么样。
- MIXED模式:上面两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。
# 十一、连接池
常用的数据库连接池有c3p0、dbcp、druid、HikariCP等。
# Druid (opens new window)
Druid是阿里巴巴开源项目,Java语言中最好的数据库连接池。
Druid大部分属性都是参考DBCP的,不仅提供了强悍的数据源实现,还内置了一个比较靠谱的监控组件。
Druid能够提供强大的监控和扩展功能。
# Spring Boot配置Druid
Druid Spring Boot Starter (opens new window) 用于帮助你在Spring Boot项目中轻松集成Druid数据库连接池和监控。
使用
在 Spring Boot 项目中加入
druid-spring-boot-starter依赖 (点击查询最新版本 (opens new window))<dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.17</version> </dependency>1
2
3
4
5添加配置
spring.datasource.url= spring.datasource.username= spring.datasource.password= spring.datasource.druid.initial-size= # ...1
2
3
4
5
# Druid参数配置表
spring.datasource.druid
- JDBC配置
| 参数 | 说明 |
|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。 如果没有配置,将会生成一个名字,格式是:"DataSource-" + System.identityHashCode(this)。 |
| url | 连接数据库的 url |
| username | 连接数据库的用户名 |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter |
| driver-class-name | 如果不配置 Druid 会根据 url 自动识别 dbType,然后选择相应的 driverClassName |
- 连接池基础配置
| 参数 | 缺省值 | 说明 |
|---|---|---|
| initial-size | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用 init 方法,或者第一次getConnection时。 |
| min-idle | 最小连接池数量 | |
| max-active | 8 | 最大连接池数量 |
| max-wait | 8 | 获取连接时最大等待时间,单位毫秒。配置了 maxWait 之后,缺省启用公平锁,并发效率会有所下降。 如果需要可以通过配置useUnfairLock 属性为 true 使用非公平锁。 |
| min-evictable-idle-time-millis | 一个连接在池中最小生存的时间(保持空闲而不被驱逐),单位是毫秒。 | |
| max-evictable-idle-time-millis | 一个连接在池中最大生存的时间,单位是毫秒。 | |
| keep-alive | false(1.0.28) | 对连接进行保活处理,缺省关闭。 连接池中的在minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行 keepAlive操作。 使用keepAlive功能后: 1)初始化连接池时会填充到minIdle数量。 2)连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作。 3)当网络断开等原因产生的由ExceptionSorter检测出来的死连接被清除后,自动补充连接到minIdle数量。 |
- PSCache配置
| 参数 | 缺省值 | 说明 |
|---|---|---|
| pool-prepared-statements | false | 是否缓存preparedStatement,也就是PSCache。 PSCache对支持游标的数据库性能提升巨大,比如说 Oracle。在 MySQL下建议关闭。 |
| max-open-prepared-statements | -1 | 指定每个连接上PSCache的大小。 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。 在 Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100。 |
- 检测连接相关配置
| 参数 | 缺省值 | 说明 |
|---|---|---|
| validation-query | 用来检测连接是否有效的SQL,要求是一个查询语句,常用select 'x'。 如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。 | |
| validation-query-timeout | 检测连接是否有效的超时时间,单位:秒。 | |
| test-on-borrow | true | 设置从连接池获取连接时,是否检查连接有效性(即执行validationQuery检测连接是否有效)。 做了这个配置会降低性能,建议关闭。 |
| test-on-return | false | 设置给连接池归还连接时,执行validationQuery检测连接是否有效。 做了这个配置会降低性能。 |
| test-while-idle | false | 用来保证连接的有效性。 申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery 检测连接是否有效。 建议配置为 true,不影响性能,并且保证安全性。 |
| time-between-eviction-runs-millis | 1分钟(1.0.14) | 间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒。 有两个含义: 1)Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis 则关闭物理连接。 2)testWhileIdle的判断依据,详细看testWhileIdle属性的说明。 |
- 监控相关配置
配置WebStatFilter
spring.datasource.druid.web-stat-filter
| 参数 | 缺省值 | 说明 |
|---|---|---|
| enabled | false | 是否启用StatFilter |
配置StatViewServlet
spring.datasource.druid.stat-view-servlet
用于展示Druid的统计信息,官方StatViewServlet配置说明 (opens new window)。
作用:
- 提供监控信息展示的HTML页面;
- 提供监控信息的JSON API。
| 参数 | 缺省值 | 说明 |
|---|---|---|
| enabled | false | 是否启用StatViewServlet(监控页面) 考虑到安全问题默认并未启动,如需启用建议设置密码或白名单以保障安全 |
| url-pattern | /druid/* | 监控页面的首页访问路径 |
| reset-enable | 允许清空统计数据开关,在StatViewSerlvet输出的html页面中,有一个功能是Reset All,执行这个操作之后,会导致所有计数器清零,重新计数。你可以通过配置参数关闭它。 | |
| login-username | 用户名 | |
| login-password | 密码 | |
| allow | 白名单。如果allow没有配置或者为空,则允许所有访问。 IP配置规则如下:不支持IPV6;可以配置为128.242.127.1/24,128.242.128.1;也可以为128.242.127.1/24 | |
| deny | 黑名单。deny优先于allow,如果在deny列表中,就算在allow列表中,也会被拒绝。 |
查看控制台的监控信息
http://localhost:8080/druid/login.html (opens new window)
- 内置Filter
你可以通过 spring.datasource.druid.filters=stat,wall,log4j ... 的方式来启用相应的内置Filter,不过这些Filter都是默认配置。
| 参数 | 缺省值 | 说明 |
|---|---|---|
| filters | 通过别名的方式配置扩展插件,属性类型是字符串,多个用逗号相隔。常用的插件有: 1)监控统计用的stat 2)日志用的log4j 3)防御SQL注入的wall |
目前为以下 Filter 提供了配置支持,请参考文档或者根据IDE提示(spring.datasource.druid.filter.*)进行配置。
- StatFilter
- WallFilter
- ConfigFilter
- EncodingConvertFilter
- Slf4jLogFilter
- Log4jFilter
- Log4j2Filter
- CommonsLogFilter
如果默认配置不能满足你的需求,你可以放弃上述这种方式,也通过配置文件来配置Filter。
配置StatFilter
spring.datasource.druid.filter.stat
用于统计监控信息,官方StatFilter配置说明 (opens new window)
| 参数 | 缺省值 | 说明 |
|---|---|---|
| enabled | false | 是否启用,Druid-Spring-Boot-Starter默认禁用StatFilter |
| log-slow-sql | 慢SQL记录 | |
| slow-sql-millis | 3000 | 配置SQL慢的标准,执行时间超过slowSqlMillis的就是慢,单位是毫秒。缺省值为3000,也就是3秒 |
| merge-sql | SQL合并配置 |
配置WallFilter
spring.datasource.druid.filter.wall
用于配置防御SQL注入攻击,官方WallFilter配置说明 (opens new window)
| 参数 | 缺省值 | 说明 |
|---|---|---|
| enabled | false | 是否启用 |
| multi-statement-allow | false | 是否允许一次执行多条语句 |
配置ConfigFilter
spring.datasource.druid.filter.config
官方ConfigFilter配置说明 (opens new window),ConfigFilter的作用包括:
- 从配置文件中读取配置;
- 从远程http文件中读取配置;
- 为数据库密码提供加密功能;
# 数据库密码加密 (opens new window)
获取加密后的数据。
Maven仓库中找到druid的包,在命令行中执行如下命令:
java -cp druid-1.0.16.jar com.alibaba.druid.filter.config.ConfigTools you_password1输出:
privateKey: publicKey: password:1
2
3配置数据源。
publickey: MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBAJX0QGFbKReek0aoC2fP7z/z808L/rvfvBV+c/3hU56TjGGAR+Ezsa9afZ1+BBZ52H0SQdVuir4GWNEHGLDwZZMCAwEAAQ== spring: datasource: druid: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://127.0.0.1:3306/demo?useUnicode=true&allowPublicKeyRetrieval=true&characterEncoding=utf8&useSSL=false&serverTimezone=GMT%2B8 username: root # 数据库登录密码(加密) password: LWOFVDVOKzdH+PV/salzQTdpxApa7cXLNs07fvW/W7I4n1yZDndQz1FYQByzfr080tihAWRfY1bzy92EkvhxJg== # 配置connection-properties,启用加密,配置公钥。 connection-properties: config.decrypt=true;config.decrypt.key=${publickey} filter: # 启动ConfigFilter config: enabled: true1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 我的Druid配置
连接阿里云数据库可以进行如下配置,参考阿里官方提供的配置参考:官方提供的配置参考 (opens new window)。
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://${base.config.mysql.hostname}:${base.config.mysql.port}/${base.config.mysql.database}?useUnicode=true&characterEncoding=utf-8&serverTimezone=Hongkong&useSSL=false&tinyInt1isBit=false
username: ${base.config.mysql.username}
password: ${base.config.mysql.password}
type: com.alibaba.druid.pool.DruidDataSource
# 连接池的设置,应用到上面所有数据源中。官方参考配置:https://github.com/alibaba/druid/wiki/DruidDataSource%E9%85%8D%E7%BD%AE
druid:
# >>> 基础配置 <<<
# 初始化大小,最小,最大线程数
initial-size: 5
min-idle: 10
# CPU核数+1,也可以大些但不要超过20,数据库加锁时连接过多性能下降
max-active: 20
# 获取连接等待超时的时间
max-wait: 6000
# 一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 600000
max-evictable-idle-time-millis: 900000
# 对连接进行保活处理,缺省关闭。使用keepAlive功能后:
# 1. 初始化连接池时会填充到minIdle数量。
# 2. 连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作。
# 3. 当网络断开等原因产生的由ExceptionSorter检测出来的死连接被清除后,自动补充连接到minIdle数量。
keep-alive: true
phyMaxUseCount: 1000
# >>> 检测连接相关配置 <<<
validation-query: SELECT 1
# 设置从连接池获取连接时,是否检查连接有效性(即执行validationQuery检测连接是否有效)。
test-on-borrow: false
# 设置给连接池归还连接时,执行validationQuery检测连接是否有效。
test-on-return: false
# 使用TestWhileIdle来保证连接的有效性
test-while-idle: true
# 间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 2000
# 打开PSCache(提升写入、查询效率),并且指定每个连接上PSCache的大小
# pool-prepared-statements: true
# max-open-prepared-statements: 20
# 1.1.4中新增加的配置,如果有initialSize数量较多时,打开会加快应用启动时间
# asyncInit: true
# >>> 监控相关配置 <<<
# Web关联监控配置
web-stat-filter:
# 默认值false
enabled: true
# 用于展示Druid的统计信息,官方配置说明:https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_StatViewServlet%E9%85%8D%E7%BD%AE
# 作用:1. 提供监控信息展示的HTML页面;2. 提供监控信息的JSON API
stat-view-servlet:
# 是否启用StatViewServlet(监控页面)默认值为false(考虑到安全问题默认并未启动,如需启用建议设置密码或白名单以保障安全)
enabled: true
url-pattern: /druid/*
# 允许清空统计数据开关,在StatViewSerlvet输出的html页面中,有一个功能是Reset All,执行这个操作之后,会导致所有计数器清零,重新计数。你可以通过配置参数关闭它。
reset-enable: false
login-username: ${base.config.mysql.username}
login-password: ${base.config.mysql.password}
# 白名单。如果allow没有配置或者为空,则允许所有访问.
# IP配置规则如下:不支持IPV6;可以配置为128.242.127.1/24,128.242.128.1;也可以为128.242.127.1/24
allow:
# 黑名单。deny优先于allow,如果在deny列表中,就算在allow列表中,也会被拒绝。
deny:
# 通过配置文件来配置内置Filter(StatFilter:监控统计、Log4jFilter:日志记录、WallFilter:防御sql注入)
filter:
# 用于统计监控信息,官方配置说明:https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_StatFilter
stat:
# Druid-Spring-Boot-Starter默认禁用StatFilter
enabled: true
# 慢SQL记录
log-slow-sql: true
# 配置SQL慢的标准,执行时间超过slowSqlMillis的就是慢。缺省值为3000,也就是3秒
slow-sql-millis: 3000
# SQL合并配置
merge-sql: true
# 配置防御SQL注入攻击,官方配置说明:https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE-wallfilter
wall:
config:
# 是否允许一次执行多条语句
multi-statement-allow: true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
# 十二、分库分表
当一张表的数据过大时,查询效率将非常低,为了提高查询操作效率,就需要对数据进行分区(分片)。
其目的将数据拆分为不同的存储单元。
拆分包括垂直分片(分库、分表)、水平分片(分库、分表)。
- 垂直分片主要用于区分数据来源;
- 水平分片主要用于扩展、负载。
Q:什么时候需要用到分片?
W:预计3年后,单表超过500万行或容量超过2GB。
# 水平分库
将一个库的数据拆分到多个库中,每个库的结构一致,数据不一致,所有库的并集为全部数据。
作用是为了从而成倍地降低IO和CPU压力。
# 垂直分库
按照业务不同,将不同的表拆分至不同的库中,每个库的结构不一致,数据也不一致。
可对标微服务模式。
# 水平分表
将一张表的数据,平摊到多张表中,每张表的结构一致,数据不一致,所有表的并集为全部数据。
作用是为了降低单表数据量,提高单次SQL执行效率。
# 垂直分表
将一张表的字段,拆分到不同的表中,每张表的结构不一致,数据也不一致。
作用是为了将热点数据和非热点数据进行分离。
# 水平分片方式
- 主键取模
- 日期区分
- 按数据范围分片
- 按枚举项字段分片
预计3年后,单表超过500万行或容量超过2GB,在创建时就进行设计。
# 逻辑库、逻辑表
在查询时,由中间件指定逻辑库、逻辑表,根据配置规则,解析SQL、生成SQL语法树,找到对应的实际库表获取数据。
# 分库分表中间件
- 客户端架构:
ShardingJDBC - 代理架构:
MyCat或者Atlas
# ShardingSphere
ShardingSphere Github官方地址:https://github.com/apache/shardingsphere (opens new window)
ShardingSphere概览 (opens new window)
Apache(当当) ShardingSphere
ShardingSphere-JDBCjavaShardingSphere-ProxyDockerShardingSphere-SidecarK8S
# MyCat
Mycat Github官方地址:https://github.com/MyCATApache (opens new window)
Apache(Alibaba ) MyCat
# 兼容MySQL且可水平扩展的数据库
目前也有一些开源数据库兼容MySQL协议,如:
但其工业品质和MySQL尚有差距,且需要较大的运维投入,如果想将原始的MySQL迁移到可水平扩展的新数据库中,可以考虑一些云数据库:
# 数据迁移至NoSQL
在MySQL上做Sharding是一种戴着镣铐的跳舞,事实上很多大表本身对MySQL这种RDBMS的需求并不大,并不要求ACID,可以考虑将这些表迁移到NoSQL,彻底解决水平扩展问题,例如:
- 日志类、监控类、统计类数据
- 非结构化或弱结构化数据
- 对事务要求不强,且无太多关联操作的数据
# 十三、FAQ
FAQ frequently asked questions 常问问题
# B树和B+树的区别
B树:多路搜索树
所有的元素不重复,节点中的数据索引从左往右递增排列;每个节点下存储该key对应的全部数据。
B+树:
是基于B树的变种,所有索引元素可重复,非叶子节点不存储数据,而叶子节点从左往右按顺序递增排列;
若为聚簇索引,叶子节点存储的数据为所有的数据;
若为非聚簇索引,叶子节点存储当前key的值;
叶子节点之间用指针连接,用于提高区间(页)之间的访问性能;
# 为什么MySQL选B+Tree数据结构
Q:为什么MySQL选择B+Tree数据结构,而非选择B Tree数据结构?
W:
由于B Tree的每个节点中不仅有其索引值还有data值,而MySQL是以页为单元进行存储数据,每一页的存储空间是有限的(默认16KB、16384字节)。若data数据较大,将导致每一页存储的节点数变小,则将导致树的深度增大,从而导致查询磁盘I/O此数据增多。
而在B+Tree数据结构中,非叶子节点只存储KEY值,且所有数据都在叶子节点排好序。那么树的高度是一定的,每页存储的KEY数据也多。所以查询某一KEY时,最多只需1~3次I/O操作。
# 为什么不建议使用UUID作为主键
UUID
UUID,长度是16字节。
有32个十六进制数值,每个十六进制数转4个二进制,32 * 4 = 128位(bit)。
通常按照8-4-4-12的顺序进行分隔,加上中间的分隔符(-),UUID有36个字符。是由32个16进制数值加4个分隔符(-)组成。例如:3F1504E0-6F89-11D3-9A0C-0905E82C3306
编码规则
- 1~8位:采用系统时间,精确到毫秒。(时间唯一性)
- 9~16位:采用底层IP地址。(服务集群唯一性)
- 17~24位:当前对象HashCode值。(内部对象唯一性)
- 25~32位:随机数。(一个对象内毫秒级唯一性)
原因
- 索引比较是按照
ASCII码逐位进行比较; - UUID无序,需要重新置位,可能造成页的分裂,且触发树平衡机制。
# 为什么建议InnoDB表必须建主键
Q:为什么建议InnoDB表必须建主键,且推荐使用整形的自增主键?
W:
主键
InnoDB是根据主键来组织数据的。
首先,若一张表没有设置主键PK,则InnoDB底层会从第一列开始,依次选择,选出所有数据都不相等的一列,作为索引的KEY。
若没有选到,则会创建一个隐藏列(rowid)来组织整张表的数据。
整形
- 在根据主键索引时,需要进行数据对比,字符串需要转换为ASCII码再逐位进行比较。固建议使用整形ID作为主键。
- 并且整形存储空间比字符串小。
int类型占4字节;long类型占8字节;string类型(UUID)占16字节。
自增
- 若KEY为自增,那么InnoDB存储单页——页(Page),将按顺序依次填充即可;
- 而若KEY不是按照自增设定,则可能会导致页的分裂,且树可能还需要做平衡。
# MySQL大小写问题
MySQL的大小写敏感性取决于具体的操作系统平台(Windows、Linux、Mac)。
因为MySQL使用文件系统的目录和文件进行保存数据库和表的定义。
- 而在
Windows中,大小写是不敏感的; - 在类
Unix中,则对大小写敏感。
# BLOB 和 TEXT 的区别
- BLOB 是一个二进制对象,可以容纳可变数量的数据。
- TEXT 是一个不区分大小写的 BLOB。
BLOB 和 TEXT 类型之间的唯一区别在于对 BLOB 值进行排序和比较时会区分大小写,对 TEXT 值不区分大小写。
# MySQL 里记录货币
NUMERIC 和 DECIMAL 类型被 MySQL 实现为同样的类型,这在 SQL92 标准允许。他们被用于保存值,该值的准确精度是极其重要的值,例如与金钱有关的数据。
例:
salary DECIMAL(9,2)
在这个例子中,9(precision)代表将被用于存储值的总的小数位数,而 2(scale)代表将被用于存储小数点后的位数。因此,在这种情况下,能被存储在 salary 列中的值的范围是从-9999999.99 到 9999999.99。
# 大表查最后的数据
Q:如何在上千万条数据中,获取最后一条?
W:
第一种:数据主键整数且自增,先查出最大主键ID,再由主键索引查询。
select * from table_1 where id = (select max(id) from table_1);
# 千万级别的表分页查询
Q:MySQL如对千万级别的表进行分页查询?
W:
利用覆盖索引,先利用索引将ID单独查出分页数据,然后再用分页的ID集合,关联大表获取所需数据。
select * from big_table a
join (
select id from big_table
where ... -- 查询条件
limit m, n
) b on a.id=b.id
2
3
4
5
6
# MySQL如何选择合适的索引
可使用EXPLAIN关键字,进行查询优化查询,选出合适的索引。
# MySQL行转列

建表语句:
CREATE TABLE `test_tb_grade` (
`ID` int(10) NOT NULL AUTO_INCREMENT,
`USER_NAME` varchar(20) DEFAULT NULL,
`COURSE` varchar(20) DEFAULT NULL,
`SCORE` float DEFAULT '0',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
insert into test_tb_grade(USER_NAME, COURSE, SCORE) values
("张三", "数学", 34),
("张三", "语文", 58),
("张三", "英语", 58),
("李四", "数学", 45),
("李四", "语文", 87),
("李四", "英语", 45),
("王五", "数学", 76),
("王五", "语文", 34),
("王五", "英语", 89);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
行转列查询语句
使用CASE WHEN 语句。
SELECT user_name ,
MAX(CASE course WHEN '数学' THEN score ELSE 0 END ) 数学,
MAX(CASE course WHEN '语文' THEN score ELSE 0 END ) 语文,
MAX(CASE course WHEN '英语' THEN score ELSE 0 END ) 英语
FROM test_tb_grade
GROUP BY USER_NAME;
2
3
4
5
6
此处之所以用MAX函数,是为了将无数据的点设为0,防止出现NULL。
# MySQL列转行

建表语句:
CREATE TABLE `test_tb_grade2` (
`ID` int(10) NOT NULL AUTO_INCREMENT,
`USER_NAME` varchar(20) DEFAULT NULL,
`CN_SCORE` float DEFAULT NULL,
`MATH_SCORE` float DEFAULT NULL,
`EN_SCORE` float DEFAULT '0',
PRIMARY KEY (`ID`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
insert into test_tb_grade2(USER_NAME, CN_SCORE, MATH_SCORE, EN_SCORE) values
("张三", 34, 58, 58),
("李四", 45, 87, 45),
("王五", 76, 34, 89);
2
3
4
5
6
7
8
9
10
11
12
列转行查询语句
使用union语句进行拼接。
select user_name, '语文' COURSE , CN_SCORE as SCORE from test_tb_grade2
union select user_name, '数学' COURSE, MATH_SCORE as SCORE from test_tb_grade2
union select user_name, '英语' COURSE, EN_SCORE as SCORE from test_tb_grade2
order by user_name,COURSE;
2
3
4
# docker安装mysql8报错1045
# 问题描述
docker新安装mysql8.0版本,使用navicat、idea连接,密码正确,但是提示权限被拒绝。
1045 - Access denied for user ‘root’@‘127.0.0.1’ (using password:Yes)
# 原因
该报错是由于目前已有的Navicat客户端连接软件还不支持Mysql8新增加的加密方式caching_sha2_password,所以我们需要修改用户的加密方式,将其改为老的加密验证方式,如mysql_native_password。
# 解决方案
1.修改密码为纯数字
可能在创建mysql时,密码使用了英文加数字和特殊字符,导致加密后无法通过验证。
2.修改mysql加密方式为mysql_native_password。
新建mysql配置文件mysqld.cnf
# 修改mysql加密插件,mysql8.0.11 默认值为caching_sha2_password,密码复杂可能验证不过
default_authentication_plugin=mysql_native_password
2
然后再启动docker,mysql容器时进行挂载。
docker run -itd -p 3306:3306 --name mysql-test -v /home/docker/mysql/mysqld.cnf:/etc/mysql/conf.d/mysqld.cnf -e MYSQL_ROOT_PASSWORD=123456 mysql
# GROUP BY报错
# 问题描述
遇到数据库重复数据,需要将数据进行分组,并取出其中一条来展示,这时就需要用到group by语句。 但是,如果mysql是高版本,当执行group by时,select的字段不属于group by的字段的话,sql语句就会报错。
报错信息如下:
Cause: java.sql.SQLSyntaxErrorException: Expression #10 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'ax_am.epia.status' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
; bad SQL grammar []; nested exception is java.sql.SQLSyntaxErrorException: Expression #10 of SELECT list is not in GROUP BY clause and contains nonaggregated column '数据库名.表名.字段名' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
2
# 原因分析
一、原理层面 这个错误发生在mysql 5.7.5 版本及以上版本会出现的问题:
mysql 5.7.5版本以上默认的sql配置是:sql_mode=“ONLY_FULL_GROUP_BY”,这个配置严格执行了"SQL92标准"。
很多从5.6升级到5.7时,为了语法兼容,大部分都会选择调整sql_mode,使其保持跟5.6一致,为了尽量兼容程序。
二、sql层面 在sql执行时,出现该原因,简单来说就是:
由于开启了ONLY_FULL_GROUP_BY的设置,如果select 的字段不在 group by 中,并且select 的字段未使用聚合函数(SUM,AVG,MAX,MIN等)的话,那么这条sql查询是被mysql认为非法的,会报错误。
# 解决方案
解决方案一(推荐):使用函数ANY_VALUE()包含报错字段。
将报错语句改成:
SELECT
USER_ID,
ANY_VALUE(problems) as problems,
ANY_VALUE(last_updated_date) as last_updated_date
FROM sys_test
GROUP BY USER_ID;
2
3
4
5
6
ANY_VALUE()函数说明
MySQL有any_value(field)函数,它主要的作用就是抑制ONLY_FULL_GROUP_BY值被拒绝。 这样sql语句不管是在ONLY_FULL_GROUP_BY模式关闭状态还是在开启模式都可以正常执行,不被mysql拒绝。 any_value()会选择被分到同一组的数据里第一条数据的指定列值作为返回数据。
解决方案二:通过sql语句暂时性修改sql_mode
去掉ONLY_FULL_GROUP_BY,重新设置值(该命令是改变了全局sql_mode,对于新建的数据库有效。):
SET @@global.sql_mode ='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
对于已存在的数据库,则需要在对应的数据库下执行:
SET sql_mode ='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
说明:
重启mysql数据库服务之后,ONLY_FULL_GROUP_BY还会出现,所以这只是暂时性的。
解决方案三:通过配置文件永久修改sql_mode。
mysql安装在服务器上和安装在本地,修改配置文件的方式有点区别。
1、Linux下修改配置文件
1)登录进入MySQL 使用命令 mysql -u username -p 进行登陆,然后输入密码,输入SQL:
show variables like '%sql_mode';
2)编辑my.cnf文件 文件地址一般在:/etc/my.cnf,/etc/mysql/my.cnf
找到sql-mode的位置,去掉ONLY_FULL_GROUP_BY
然后重启MySQL;
有的my.cnf中可能没有sql-mode,需要追加:
sql-mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION;
注意要加入到[mysqld]下面,如加入到其他地方,重启后也不生效。
3)修改成功后重启MySQL服务
service mysql restart
重启好后,再登录mysql,输入SQL:
show variables like ‘%sql_mode’;
如果没有ONLY_FULL_GROUP_BY,就说明已经成功了。
2、window下修改配置文件 1)找到mysql安装目录,用记事本直接打开my.ini文件
2)编辑my.cnf文件,在[mysql]标签下追加内容

3)重启mysql 服务。
# 十四、MySQL相关资料
MySQL官网:https://www.mysql.com (opens new window)
MySQL(5.6版本)安装(Windows环境) (opens new window)
MySQL5.7的安装与配置(centos7环境) (opens new window)
SQL 基础教程中文文档 (opens new window)
ShardingSphere Github官方地址:https://github.com/apache/shardingsphere (opens new window)
ShardingSphere概览 (opens new window)
Mycat Github官方地址:https://github.com/MyCATApache (opens new window)